2026. 3. 16. 08:00ㆍIT_Tech

📌 같이 보면 좋은 글
실전에서 배운 교훈: 260개 API를 다루는 엔터프라이즈 LLM 서비스 구축기
LLM 기반 엔터프라이즈 서비스를 구축할 때 가장 중요한 것은 무엇일까요? 정교한 프롬프트 작성일까요, 아니면 최신 모델 선택일까요? 실제 프로젝트 경험을 통해 대규모 AI 서비스 구축의 핵심 전략을 살펴봅니다.
📚 목차
- 프롬프트 엔지니어링의 한계
- 컨텍스트 엔지니어링이란?
- Flava AI 어시스턴트의 차별점
- 대규모 정보 관리의 도전과제
- 점진적 공개 전략의 4단계
- 실제 구현 사례와 교훈
- 자주 묻는 질문 (FAQ)
프롬프트 엔지니어링만으로는 부족하다
"너는 10년차 전문가야, 답변은 JSON으로 해줘." 이런 식의 프롬프트 엔지니어링은 이제 AI 개발자라면 누구나 아는 기본 테크닉입니다. 하지만 27개의 클라우드 제품과 260개 이상의 API를 연동해야 하는 실전 상황에서는 이야기가 달라집니다.
대규모 클라우드 플랫폼용 AI 어시스턴트를 개발하면서 직면한 가장 큰 문제는 정보의 폭발이었습니다. 아무리 뛰어난 AI라도 수백 페이지의 문서를 한꺼번에 건네주며 "알아서 처리해"라고 하면 제대로 된 성과를 내기 어렵습니다.
💡 핵심 인사이트: LLM 애플리케이션의 성공은 "무엇을 물어볼 것인가"보다 "어떤 정보를 언제 제공할 것인가"가 더 중요합니다.
컨텍스트 엔지니어링: 정보를 선별하는 기술
컨텍스트 엔지니어링(Context Engineering)은 LLM에게 필요한 정보만 선별해서 제공하는 것입니다. 신입 개발자에게 10년 치 문서를 던져주는 대신, 필요한 순간에 필요한 문서만 딱 집어서 주는 좋은 사수처럼 말이죠.
"요즘 LLM은 컨텍스트 윈도우가 수십만 토큰인데 괜찮지 않나요?"라고 생각할 수 있습니다. 하지만 최근 연구 결과는 다른 이야기를 들려줍니다.
📊 양이 많으면 성능이 떨어진다
2025년 10월 발표된 연구에 따르면, 컨텍스트 길이가 늘어나면 GPT-4o와 Claude-3.5-Sonnet 같은 최신 모델도 최대 13.9%에서 85%까지 성능이 하락했습니다. 단지 입력이 길어졌다는 이유만으로 말이죠. 64K 토큰은 A4 용지 70페이지 분량인데, 대화 히스토리와 API 응답까지 합치면 순식간에 소진됩니다.
🔍 질 낮은 정보가 섞이면 판단력이 흐려진다
'Context Rot' 연구에서는 정답과 유사하지만 관계없는 정보를 섞었을 때, 컨텍스트가 길어질수록 오답을 내는 비율이 급증한다는 결과를 발표했습니다. 더 심각한 것은 GPT 계열에서 매우 당당하게 가짜 정보를 생성하는 환각 현상이 발생한다는 점입니다.
📌 관련 자료: AI 시스템 구축에 관심 있으시다면 유니브 AI 플랫폼 가이드도 참고해보세요.
엔터프라이즈 AI 어시스턴트는 무엇이 다른가?
일반적인 RAG(Retrieval-Augmented Generation) 챗봇은 "나 대신 문서 읽고 요약해줘"를 수행합니다. 하지만 이번 프로젝트에서 구축한 AI 어시스턴트는 한 단계 더 나아갑니다. 사용자의 권한으로 실제 API를 호출해서 현재 리소스 상태를 직접 확인합니다.
비교: 일반 RAG vs 엔터프라이즈 AI
| 구분 | 일반 RAG 챗봇 | 엔터프라이즈 AI 어시스턴트 |
|---|---|---|
| 정보 소스 | 문서, 가이드 | 문서 + 실시간 API 호출 |
| 답변 방식 | 일반론적 가이드 | 내 상황 맞춤 진단 |
| 예시 | "네트워크 상태를 확인해보세요" | "현재 VPC ACL이 닫혀 있네요" |
점진적 공개: 4단계 전략
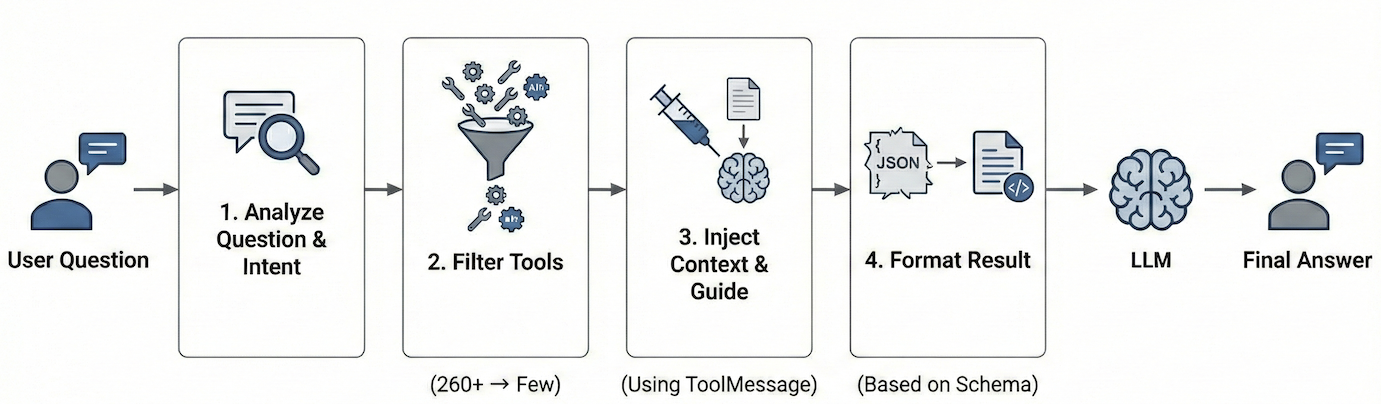
프로젝트에서 택한 핵심 전략은 '점진적 공개(Progressive Disclosure)'입니다. 처음부터 모든 정보를 제공하는 대신, 사용자의 질문과 현재 진행 상태에 따라 필요한 정보만 적절히 제공합니다.
1단계: 필요한 도구만 골라내기
260개 API를 모두 로드하지 않습니다. 사용자가 "Redis 클러스터 상태 알려줘"라고 물으면, 27개 제품 중 Redis 관련 도구 8개만 선별해서 보여줍니다. 나머지 252개는 컨텍스트에 올리지도 않습니다.
2단계: 필요한 사용법만 알려주기
Object Storage는 내부용과 외부용(CDN) 설정이 다릅니다. 이런 힌트는 실제 Object Storage API를 호출할 때만 제공합니다. 처음에는 시스템 프롬프트에 추가하는 방식을 썼지만, 프롬프트끼리 충돌하는 문제가 발생했습니다.
⚠️ 실전 교훈: "반드시 검색 결과로만 답변하라"는 시스템 프롬프트와 "UI를 먼저 안내하라"는 가이드라인이 충돌하여 LLM이 검색 없이 환각을 일으켰습니다.
3단계: 모의 도구 메시지 전략
해결책은 가이드라인을 시스템 프롬프트 대신 '도구 메시지(ToolMessage)' 형태로 제공하는 것이었습니다. LLM은 도구 실행 결과를 저장할 때 이 형식을 사용하는데, 가이드라인을 마치 도구 실행 결과처럼 제공하니 '참고 정보'로 인식하게 되었습니다.
정보의 우선순위가 명확해진 구조
- 시스템 프롬프트: "반드시 검색된 결과로만 답변하세요" → 행동 강령
- 응답 가이드라인: "삭제 시 UI를 먼저 안내하세요" → 참고 데이터
4단계: API 응답 재구성
260개 API의 모든 응답 스키마를 처음부터 주입하는 것은 토큰 낭비입니다. 실제 API 응답이 돌아온 순간, 해당 데이터를 해석하기 위한 스키마 정보만 덧붙여 전달합니다.
# Schema
services!: array
name!: string
flavor_ref!: string // 서버 사양 ID
status?: "active" | "error"
# Data (YAML 형식)
services:
- name: "prod-redis"
flavor_ref: "m5.large"
status: "active"
JSON보다 YAML을 선택한 이유는 가독성입니다. 토큰 수 차이가 크지 않으면서도 훨씬 읽기 쉬웠습니다.
📌 유사 기술: 효율적인 데이터 관리에 관심 있으시다면 CPU 캐시 메모리 가이드도 살펴보세요.
덜어내는 것이 진짜 기술이다
컨텍스트 엔지니어링의 핵심을 한 마디로 요약하면 이렇습니다: "노이즈를 줄이고, 신호(signal)만 남기세요."
LLM의 성능이 아무리 좋아져도 불필요한 정보는 판단을 흐려지게 만듭니다. 개발자가 코드를 짤 때 필요한 모듈만 import 하듯, AI에게도 그 순간에 가장 필요한 정보만 제공하는 것. 그것이 대규모 AI 서비스를 똑똑하게 만드는 비결입니다.
💎 핵심 요약
- 엔터프라이즈 LLM 서비스에서는 프롬프트보다 컨텍스트 엔지니어링이 중요
- 컨텍스트가 길어지면 성능이 최대 85%까지 하락할 수 있음
- 점진적 공개: 필요한 정보를 필요한 순간에만 제공
- 시스템 프롬프트 충돌은 도구 메시지 전략으로 해결
- 노이즈를 줄이고 신호만 남기는 것이 핵심
실무 적용 가이드
실제로 엔터프라이즈 LLM 서비스를 구축할 때 다음 체크리스트를 활용해보세요:
✅ 구축 전 체크리스트
- 정보 규모 파악: 다룰 API, 문서, 도구의 개수 확인
- 토큰 예산 계산: 평균 대화에서 소비될 토큰 수 추정
- 도구 분류: 제품군별, 기능별로 도구 그룹화
- 가이드라인 우선순위: 어떤 상황에 어떤 정보가 필요한지 매핑
- 스키마 최적화: API 응답 스키마를 간결하게 정리
실제 구현 팁
1. 도구 선별 로직 구현
사용자 질문을 분석하여 관련 제품/기능 키워드를 추출하고, 해당하는 도구만 컨텍스트에 로드하세요.
2. 조건부 가이드라인 매칭
가이드라인마다 '조건'과 '내용'을 분리하여 저장하고, LLM에게 먼저 조건만 보여주고 선택하게 하세요.
3. 응답 형식 통일
API 응답은 스키마 + YAML 형식으로 통일하여 LLM이 일관되게 해석하도록 하세요.
📌 추가 학습: 양자 컴퓨팅 개념도 첨단 기술 이해에 도움이 됩니다.
자주 묻는 질문 (FAQ)
Q1. 컨텍스트 엔지니어링과 프롬프트 엔지니어링의 차이는?
프롬프트 엔지니어링은 LLM에게 "어떻게 답변할지" 지시하는 것이고, 컨텍스트 엔지니어링은 "어떤 정보를 언제 제공할지" 설계하는 것입니다. 프롬프트는 지침, 컨텍스트는 정보 제공 전략입니다.
Q2. 소규모 프로젝트에도 필요한가요?
API가 10개 미만이고 문서가 몇 페이지 수준이라면 굳이 필요하지 않습니다. 하지만 다루는 정보가 50개 이상의 엔드포인트나 수십 페이지의 문서를 넘어가면 컨텍스트 엔지니어링이 필수가 됩니다.
Q3. 점진적 공개의 성능 개선 효과는?
실제 프로젝트에서는 토큰 사용량을 약 70% 절감하면서도 응답 정확도가 향상되었습니다. 특히 복잡한 멀티턴 대화에서 환각 현상이 크게 줄어들었습니다.
Q4. 어떤 모델에서 가장 효과적인가요?
컨텍스트 엔지니어링은 모델과 무관한 아키텍처 전략입니다. GPT-4, Claude, Gemini 등 어떤 LLM을 사용하더라도 동일하게 적용할 수 있으며, 모델 성능이 높을수록 효과가 더 명확합니다.
Q5. 구현 시 가장 어려운 부분은?
가장 어려운 것은 "어떤 정보가 언제 필요한지" 판단하는 로직 설계입니다. 사용자 질문의 의도 파악, 도구 매칭, 가이드라인 선별 등 각 단계마다 정교한 규칙이나 별도의 LLM 호출이 필요할 수 있습니다.
마치며
엔터프라이즈 LLM 서비스 구축은 단순히 최신 모델을 선택하거나 프롬프트를 잘 작성하는 것 이상의 전략이 필요합니다. 실제 프로젝트 경험은 대규모 정보를 다루는 AI 시스템에서 정보 설계가 얼마나 중요한지 보여줍니다.
이 글에서 다룬 컨텍스트 엔지니어링 전략은 실제 구축 과정에서 시행착오를 거쳐 검증된 방법론입니다. 여러분의 프로젝트에도 적용해보시고, 더 나은 방법을 발견하신다면 공유 부탁드립니다!
'IT_Tech' 카테고리의 다른 글
| 테스트 코드도 이제 AI가 짜줍니다: Playwright와 LLM으로 완성하는 차세대 QA 자동화 가이드 (0) | 2026.03.25 |
|---|---|
| 서버리스 vs 컨테이너: 클라우드 배포 전략 (0) | 2026.03.18 |
| 오라클 독점 시대의 종말, PostgreSQL이 가져온 데이터베이스 혁명 (1) | 2026.03.11 |
| 스타링크(Starlink) 위성 인터넷 총정리 - 가격, 설치방법, 사용후기까지 (1) | 2026.02.18 |
| 소중한 내 정보, 랜섬웨어로부터 지키는 필승 전략! (0) | 2026.02.16 |